Open-Vocabulary 3D Instance Segmentation
with 2D Mask Guidance
CVPR 2024
arXiv Supplementary Paper Code Video
TL;DR: We propose Open3DIS addressing 3D Instance Segmentation with Open-Vocabulary queries.
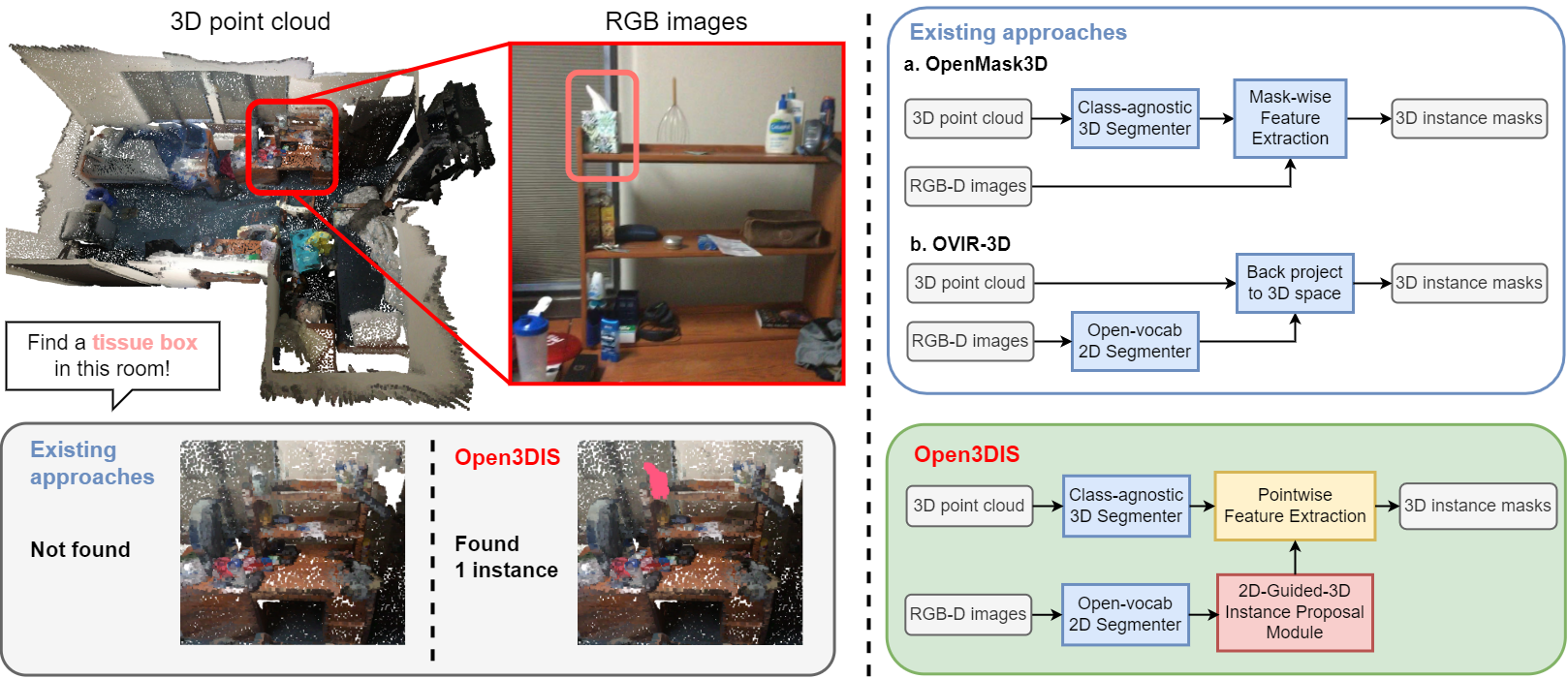
We introduce Open3DIS , a novel solution designed to tackle the problem of Open-Vocabulary Instance Segmentation within 3D scenes. Objects within 3D environments exhibit diverse shapes, scales, and colors, making precise instance-level identification a challenging task. Recent advancements in Open-Vocabulary scene understanding have made significant strides in this area by employing class-agnostic 3D instance proposal networks for object localization and learning queryable features for each 3D mask. While these methods produce high-quality instance proposals, they struggle with identifying small-scale and geometrically ambiguous objects. The key idea of our method is a new module that aggregates 2D instance masks across frames and maps them to geometrically coherent point cloud regions as high-quality object proposals addressing the above limitations. These are then combined with 3D class-agnostic instance proposals to include a wide range of objects in the real world.
To validate our approach, we conducted experiments on three prominent datasets, including ScanNet200, S3DIS, and Replica, demonstrating significant performance gains in segmenting objects with diverse categories over the state-of-the-art approaches.


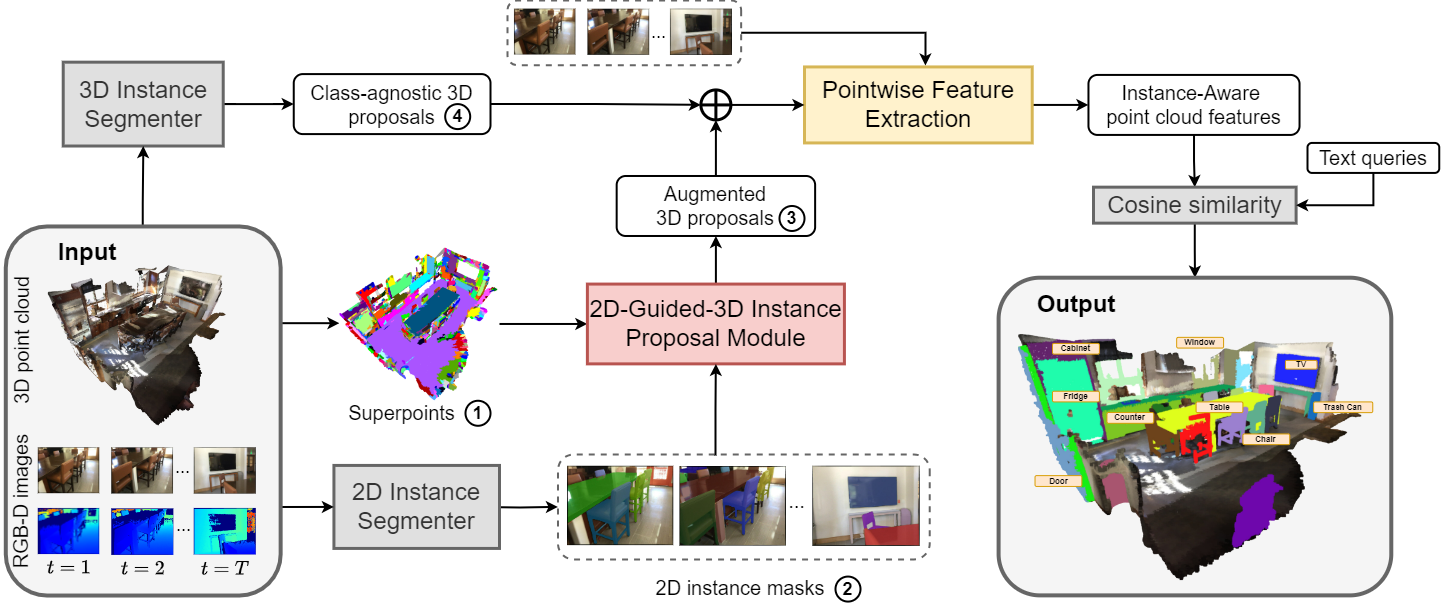
A pre-trained class-agnostic 3D Instance Segmenter proposes initial 3D objects, while a 2D Instance Segmenter generates masks for video frames. Our 2D-guide-3D Instance Proposal Module combines superpoints and 2D instance masks to enhance 3D proposals, integrating them with the initial 3D proposals. Finally, the Pointwise Feature Extraction module correlates instance-aware point cloud CLIP features from multiview images with text embeddings to generate the ultimate instance masks.
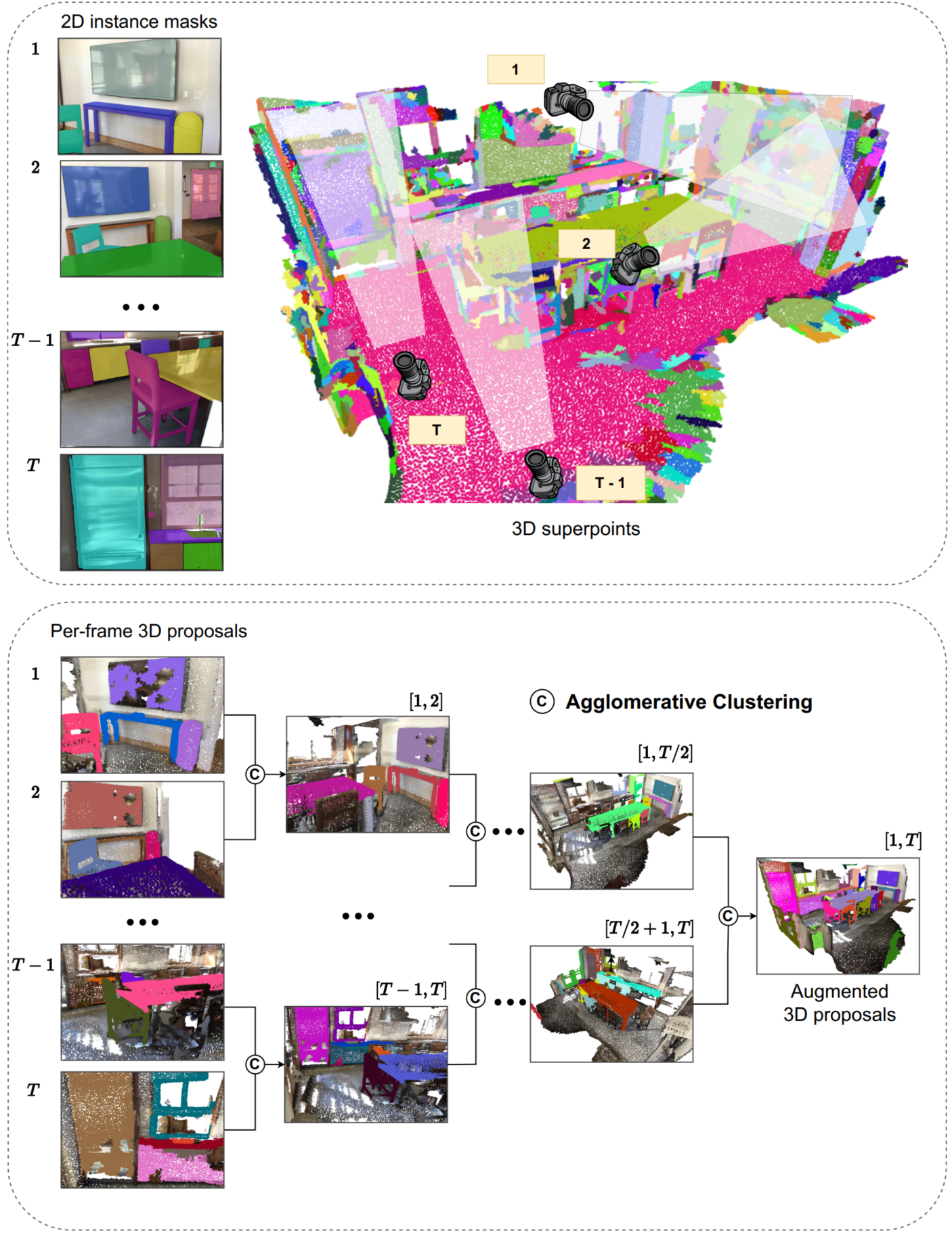
(Top) The 2D-G-3DIP module utilizes 2D per-frame instance masks to generate per-frame 3D proposals by leveraging 3D superpoints. (Bottom) Our proposed hierarchical merging. These proposals are considered point cloud regions and undergo a hierarchical merging process across multiple views, resulting in the final Augmented 3D proposals
ScanNet200
OV-3DIS results on ScanNet200. Our proposed method achieves the highest AP, outperforming previous methods in all metrics. The best results are in bold. [Using 3D backbone ISBNet or Mask3D gains no significant different. Below 3D exps use ISBNet] (updated on 2024, Mar. 19th).
\[ \begin{array}{lccccccc} \hline \textbf{Method} & \text{Backbone3D} & \textbf{AP} & \textbf{AP$_{50}$} & \textbf{AP$_{25}$} & \textbf{AP$_{head}$} & \textbf{AP$_{com}$} & \textbf{AP$_{tail}$} \\ \hline \text{OpenScene} & \text{DBScan} & 2.8 & 7.8 & 18.6 & 2.7 & 3.1 & 2.6 \\ \text{OpenScene} & \text{Mask3D} & 11.7 & 15.2 & 17.8 & 13.4 & 11.6 & 9.9 \\ \text{SAM3D (SAM)} & & 6.1 & 14.2 & 21.3 & 7.0 & 6.2 & 4.6 \\ \text{OVIR-3D (G-SAM)} & & 13.0 & 24.9 & 32.3 & 14.4 & 12.7 & 11.7 \\ \text{OpenIns3D (Synthetic-Scene)} & \text{Mask3D} & 8.8 & 10.3 & 14.4 & 16.0 & 6.5 & 4.2 \\ \text{OpenMask3D} & \text{Mask3D} & 15.4 & 19.9 & 23.1 & 17.1 & 14.1 & 14.9 \\ \hline \textbf{Ours} \text{ (G-SAM)} & & 18.2 & {26.1} & 31.4 & 18.9 & 16.5 & {19.2} \\ \textbf{Ours} \text{ (3D)} & \text{ISBNet} & {18.6} & 23.1 & 27.3 & {24.7} & {16.9} & 13.3 \\ \textbf{Ours} \text{ (3D)} & \text{Mask3D} & {18.9} & 24.3 & 28.3 & {23.9} & {17.4} & 15.3 \\ \textbf{Ours} \text{ (3D + G-SAM)} & \text{ISBNet} & \textbf{23.7}& \textbf{29.4} & {32.8} & \textbf{27.8} & {21.2} & {21.8} \\ \textbf{Ours} \text{ (3D + G-SAM)} & \text{Mask3D} & \textbf{23.7} & {29.2} & \textbf{33.1} & 26.4 & \textbf{22.5} & \textbf{21.9} \\ \hline \end{array} \]
Class-agnostic 3DIS evalutaion results on ScanNet200! (updated on 2024, Mar. 29th) [not in arxiv Dec. 17th] *: unofficial.
\[ \begin{array}{lccc} \hline \textbf{Method} & \textbf{AP} & \textbf{AP$_{50}$} & \textbf{AP$_{25}$} & \textbf{AR} & \textbf{AR$_{50}$} & \textbf{AR$_{25}$} \\ \hline \text{Superpoint} & 5.0 & 12.7 & 38.9 \\ \text{DBSCAN} & 1.6 & 5.5 & 32.1 \\ \text{OVIR-3D* (Detic)} & 14.4 & 27.5 & 38.8 \\ \text{Mask Clustering (CropFormer)} & 17.4 & 33.3 & 46.7 \\ \hline \textbf{Ours} \text{ (3D)} & 40.2 & 50.0 & 54.6 & 66.8 & 80.4 & 87.4 \\ \textbf{Ours} \text{ (G-SAM)} & 29.7 & 45.2 & 56.8 & 49.0 & 70.0 & 83.2 \\ \textbf{Ours} \text{ (SAM)} & 31.5 & 45.3 & 51.1 & 61.2 & 87.1 & 97.5 \\ \textbf{Ours} \text{ (3D + G-SAM)} & 34.6 & 43.1 & 48.5 & 66.2 & 81.6 & 91.4 \\ \textbf{Ours} \text{ (3D + SAM)} & 41.5 & 51.6 & 56.3 & 74.8 & 90.9 & 97.8 \\ \hline \end{array} \]
ScanNet++
Class-agnostic 3DIS evalutaion results on ScanNet++. Using all frames is the same as OpenMask3D sample rate: 10. We use 1554 class instance masks. (Not subset of 100 semantic classes as link) (updated on 2024, Mar. 29th) [not in arxiv Dec. 17th].
\[ \begin{array}{lccc} \hline \textbf{Method} & \textbf{AP} & \textbf{AP$_{50}$} & \textbf{AP$_{25}$} & \textbf{AR} & \textbf{AR$_{50}$} & \textbf{AR$_{25}$} & \textbf{NOTE} \\ \hline \text{ISBNet (3D)} & 6.2 & 10.1 & 16.2 & 10.9 & 16.9 & 25.2 & \text{pretrained Scannet200}&\\ \hline \text{SAM3D} & 7.2 & 14.2 & 29.4 &\\ \text{SAM-guided Graph Cut} & 12.9 & 25.3 & 43.6 &\\ \text{Segment3D} & 12.0 & 22.7 & 37.8 &\\ \text{SAI3D (SAM)} & 17.1 & 31.1 & 49.5 &\\ \text {SAMPro3D (SAM)} & 18.9 & 33.7 & 51.6 & \\ \hline \textbf{Ours} \text{ (SAM)} & 18.5 & 33.5 & 44.3 & 35.6 & 63.7 & 82.7 & \text{100 frames per scene}&\\ \textbf{Ours} \text{ (SAM)} & 20.7 & 38.6 & 47.1 & 40.8 & 75.7 & 91.8 & \text{all frames per scene}&\\ \hline \end{array} \]










@inproceedings{nguyen2023open3dis,
title={Open3DIS: Open-Vocabulary 3D Instance Segmentation with 2D Mask Guidance},
author={Phuc D. A. Nguyen and Tuan Duc Ngo and Evangelos Kalogerakis and Chuang Gan and Anh Tran and Cuong Pham and Khoi Nguyen},
year={2024},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}}